Semantisk samhandlingsevne
Semantisk interoperabilitet sikrer presis formatering og at betydningen av data som utveksles beskyttes og ikke endrer mening i dialogen mellom ulike aktører. Med andre ord, det som er sendt er det som blir forstått. I EIF-modellen dekker semantisk interoperabilitet både semantikk og syntaks.
Digital assistent hjelper brukeren med tilgang til data, tjenester og informasjon på tvers av alle sektorer. Velfungerende brukerreiser og livshendelser fordrer at brukerens data følger brukernes steg mellom de ulike tjenestene som aktørene i offentlig og privat sektor tilbyr eller forvalter. Forståelsen av hva disse dataene betyr og hvordan de er definert ligger til den semantiske utfordringen. I offentlig sektor kan dette ofte være regulert direkte gjennom lovtekst, men ikke alltid.
Skal informasjon flyte maskinelt og i størst mulig grad automatisert vil det stille krav til datakvalitet og løsninger for å kunne gjøre denne type semantiske avklaringer mellom tjenesteytere som skal samspille opp mot brukerreiser og funksjonene en digital assistent skal ha. Det må for eksempel avklares om “samboer” i NAVs tjenester er det samme som SKD sin “samboer” i samme brukerreise.
Når offentlige virksomhetene har dokumentert hvilke data de forvalter – og hvordan disse dataene inngår i tjenestene til virksomheten – er det lagt til rette for at en digital assistent kan bistå brukeren gjennom sin brukerreise på tvers av de mange virksomhetene.
Den digitale assistenten vil inngå i og bruke et felles økosystem for samhandling. Dermed har den samme tilnærming til semantikken som økosystemet selv, med en tilleggsdimensjon som går på semantikken i brukerdialogen. Det vil si å sikre evnen til å tolke dialogen korrekt.
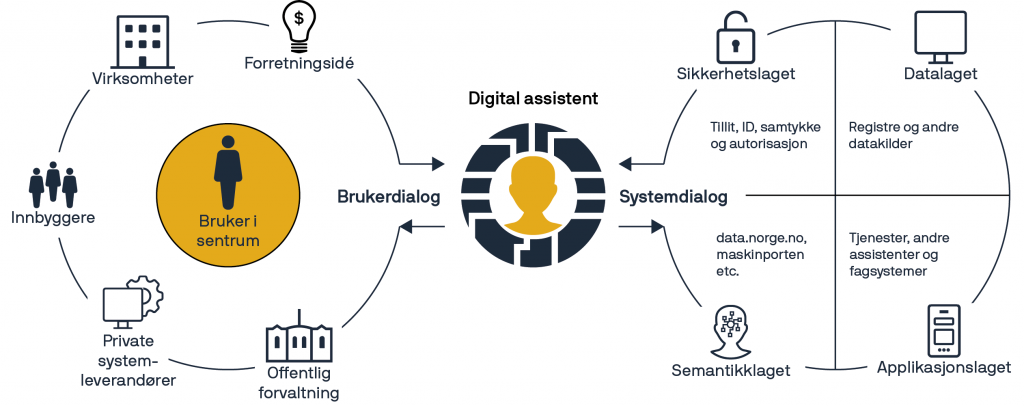
Brukerdialogen
Brukerdialogen vil ha ulikt presisjonsnivå fra enkle binære valg ( ja/nei), skjemautfylling, via tekstlig kommunikasjon til muntlig kommunikasjon. Kompleksiteten er økende, og i sammenhengende tjenester vil vi også se at et og samme begrep vil kunne ha endret meningsinnhold avhengig av lovanvendelse. Begreper som benyttes kan også ha en «gjelder fra» og «holdbar til» dimensjon.
Muntlig dialog og semantikkutfordring
Semantikk er en viktig del av eksisterende språkteknologiske løsninger for eksempel ved maskinoversettelser mellom språk og målformer, samtale-roboter (chatbots), talegjenkjenning og talesyntese (kunstig tale). I forbindelse med kunstig intelligens blir det også brukt for å kalkulere sannsynligheter (for eksempel ved at brukeren søker ett uttrykk heller enn et annet), for å tolke ytringer osv. Slike bruksområder vil også være relevante for en digital assistent.
Videre i brukerdialogen er kunnskapen om «brukeren» (brukerprofilen) og «emnet» (fagområdet) en tilleggsdimensjon ift. den semantiske forståelsen av brukerens behov. På området «brukeren» kan dialogen understøttes av samspillet med en digital assistent. På området «emnet» kan dialogen i en viss grad ha hjelp av begrepskatalogen, som bygger på en godt definert taksonomi og ontologi.
Videre er brukerdialogen ofte en blanding av skriftlig og muntlig kommunikasjon. Spesielt for den muntlige delen kan det være upresist med rom for flere tolkninger. Da området er noe upløyd mark, må videre arbeid med digital assistent innebære mye læring og forvaltningen vil ha stor nytte av et samarbeid på tvers av ulike aktører og fagområder. Slike fagområder inkluderer for eksempel akademia og private aktører som jobber med produktutvikling på dette feltet, samt klarspråk-miljøet, Språkrådet, Nasjonalbiblioteket, og Arkivverket.
Systemdialogen
I systemdialogen er behovene og utfordringene til en digital assistent stort sett de samme som for vanlige applikasjoner. Det finnes lang erfaring med bruk av data fra eksterne kilder. I tillegg har Digdir etablert Felles Data Katalog (FDK), som har gitt en mer strukturert tilnærming til fagområdet – tilrettelegging for deling av data.
Med utgangspunkt i at digital assistent også engasjerer nye utviklings- og forvaltningsgrupper, gjentas kjernen fra argumentasjon for hvordan utfordringene med deling og tilgjengeliggjøring av data kan og bør løses. Denne argumentasjonen og problemvinklingen er også akseptert og anerkjent i offentlig sektor, men det gjenstår et betydelig arbeide med å identifisere, beskrive og tilgjengeliggjøre data.
Semantikk er nøkkelen/forutsetningen for at en digital assistent skal kunne koble kontekstdata med det relevante regelverket som regulerer den aktuelle konteksten. Å jobbe systematisk med tydeliggjøring og koordinering av begrepene slik de er brukt, vil være viktig for effektiv informasjonsutveksling. For å kunne støtte automatisering av rettsregler, er det behov for tilsvarende bevissthet og innsats rundt begrepene som brukes i lovverket.
Oppsummering om semantisk samhandlingsevne
Forutsetningene for en vellykket gjennomføring er at vi får en oppslutning og ett felles eierskap til behovet for å dokumentere hvilke data og tjenester den enkelte data- og tjenesteeier forvalter og hvordan disse skal tolkes korrekt og i tillegg hvordan dette legger til rette for orden i eget hus og økt deling av data.
Data og tjenester er to sider av samme sak. Eksempelvis må det offentlige ha like skarpt fokus på data som tjenester – og informasjonsforvaltningsarbeidet må i større grad fokusere på brukerdialogen.